The LayerOne Capture The Flag (CTF) event is a traditional security competition hosted by the folks at Qualcomm at the LayerOne Security Conference. There were various challenges ranging in difficulty that required competitors to uncover flags by exploiting security vulnerabilities. This is a quick write up of one of the more complex challenges (LogViewer):
Part I
The first part of the challenge asked competitors to calculate the SHA-256 hash of the web service binary running on the CTF server. The provided URL displayed the following page:

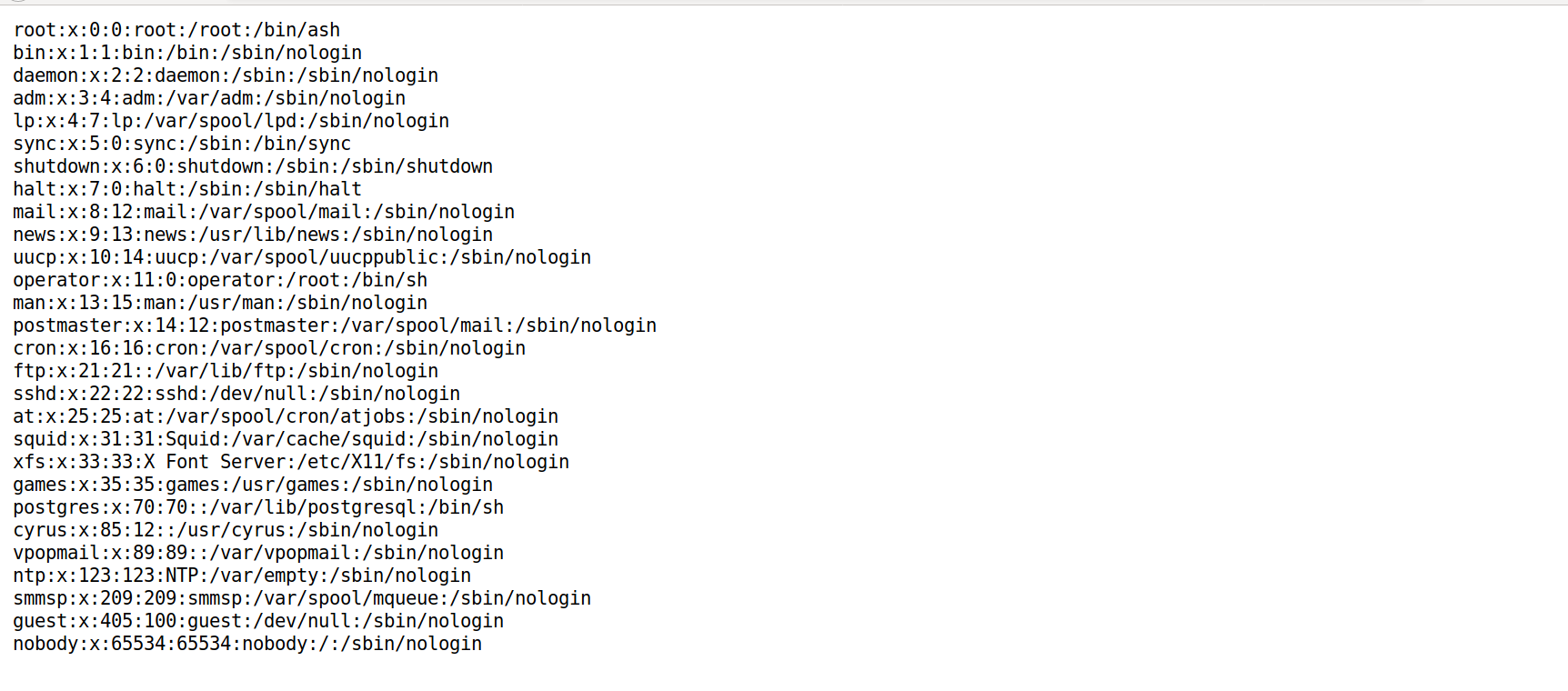
The page was a simple form with an input field. Trying different inputs revealed that the form returned the content of the file provided. As an example, the contents of /etc/passwd was read as it is typically world-readable on a Linux system:
The web service allowed an arbitrary read of a user defined file on the server. Theoretically we could use this vulnerability to download the web service binary itself, but there was a challenge with this approach: we did not know the correct path to the web service binary.
This was solved by looking through /proc. On typical Linux systems there are a few symlinks under /proc; notably /proc/self, which links to the process that’s reading /proc/self. So accessing /proc/self through the web service will point to the web service process.
Note that every process running on a Linux system is represented by a directory under /proc (named after the pid). Each of these directories contains a set of typical directories and links. Notably the symlink exe is a link to the currently-running program. The following is a set of details of /exe from the proc man page:

Thus by accessing /proc/self/exe via the web form input we were able to download the web service binary directly:

After saving the binary we calculated the SHA-256 hash of the file and captured the flag:
Flag: 04c0bd03d648ea2bee457cb86e952bd7d72bda35805b2e6576bafa2c1d270d90
Part II
The second part of this challenge was to read the /flag.txt file on the CTF server by using the web service binary we obtained in Part I.
In order to begin reversing of the web service binary, we pulled the HTML file from the challenge website and set it up on a local test environment. When we first ran the program in Ubuntu 18.04 and tried to read /flag.txt using the webform, it returned the following error:

This error message told us that the program was expecting to read the file /etc/alpine-release and use it somehow. To verify this, we created a docker container running Alpine Linux. After setting up the container, we got the following response from accessing the flag file:

A password was required (via GET parameters) to access the flag file and we had to figure out this password by reverse engineering the web service binary.
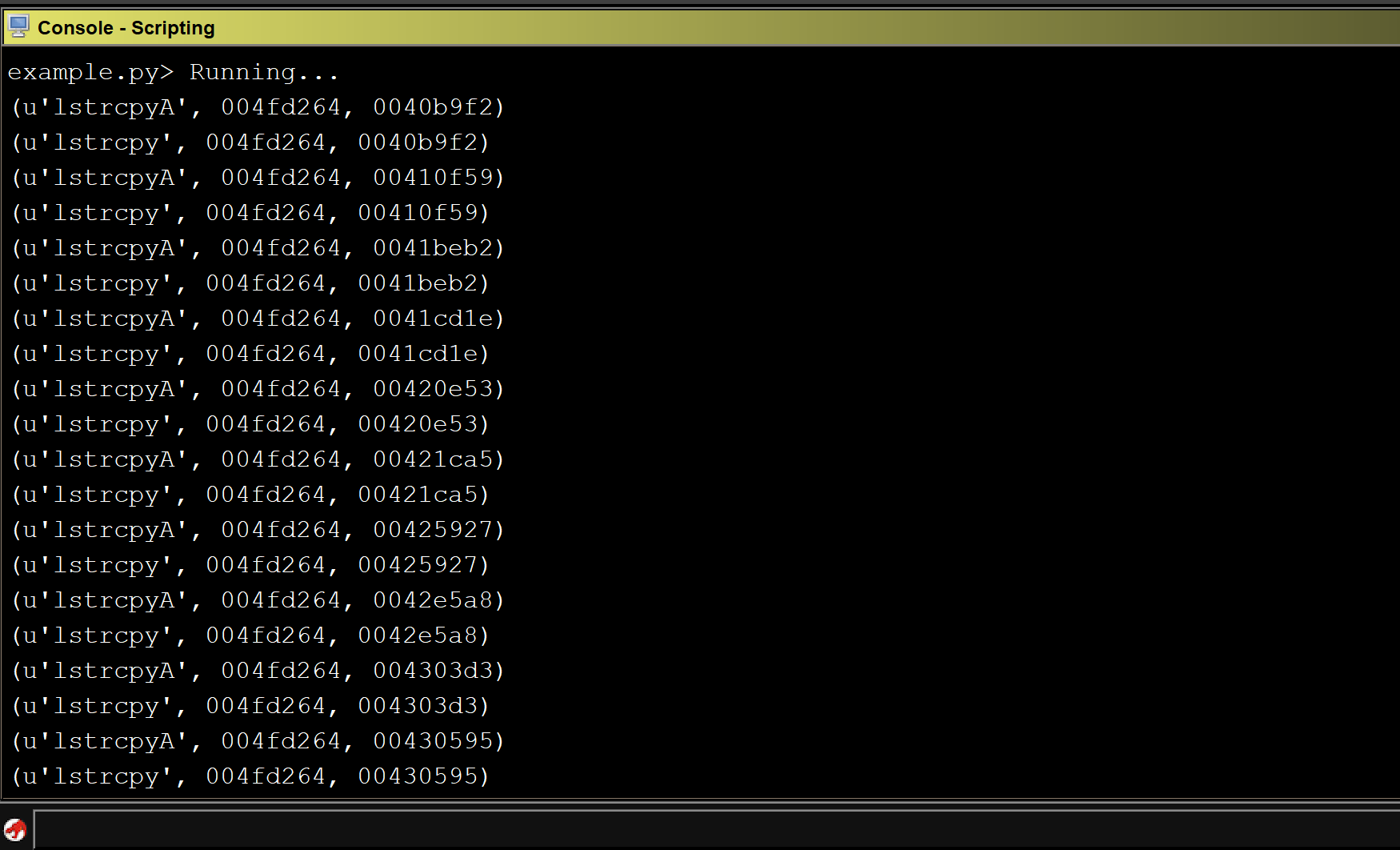
The binary was written in Go and was statically linked, making it a bit messy to view in IDA Pro. After we annotated and analyzed various functions, we reached the following conclusion regarding program flow:

The program first reads the form input and checks if it contains /flag.txt. If the user input does contain /flag.txt, it would check the password provided by the user and return its content if the password is correct. Otherwise, it would return the content of the user-specified file if it is present on the system.
Looking at the checkPassword functions, there were several cmp instructions that checked for the total length and byte values in the password. The following are the constraints for the password:
Constraint 1: The length of the password is at least 7 bytes (cmp rdx, 7)

Constraint 2: The 4th and 6th bytes of the password must be equal (cmp [rax+06], cl)

Constraint 3: The 1st byte of the password must be c (cmp BYTE PTR [rsp+0x3f], dl)

Constraint 4: The 3rd byte of the password must be e (cmp BYTE PTR [rsp+0x3f],cl)

Constraint 5: The 0th byte of the password must be Z (cmp BYTE PTR [rax], 0x5a)
Constraint 6: The 4th byte of the password must be x (cmp BYTE PTR [rax+4], 0x78)

Constraint 7: The 2nd byte of the password must be # (cmp BYTE PTR [rsp+0x3f], cl)
Constraint 8: The password’s 4th byte cannot be equal to the 5th byte plus 5 (cmp BYTE PTR [rsp+0x5],cl)
Constraint 9: The length of the password must be at least 9 bytes:

Constraint 10: The password’s third and fourth bytes have to be equal to the last two bytes:

To summarize all constraints:
Must be at least 7 bytes
Byte 4 and 6 must be equal
Byte 1 must be c
Byte 3 must be e
Byte 0 must be Z
Byte 4 must be x
Byte 2 must be #
Byte 4 must not be equal to byte 5 + 5 more chars
Must be at least 9 bytes
Bytes 3 and 4 must be equal to the last two bytes
After many trials and errors, we came up with the following form of the password:
Zc#exZx#e
Given this will be passed as a GET parameter it was important for us to URL-encode the “#” character as it would otherwise be interpreted as a fragment identifier.
After generating the password we queried the CTF server with the following encoded payload:
https://exeter.d53b608415a7222c.ctf.land?path=/flag.txt&password=Zc%23exZx%23e
Accessing the URL above gave us the flag:

Flag: EngineeringFlagReversingReversed
And such is the story of the LogViewer challenge. We really enjoyed capturing this multifaceted flag, and we had a blast competing at the LayerOne CTF. Thanks again to the organizers of the conference and CTF. We are looking forward to the next one.